Introduction of InternVL 1.5 Series#
InternVL-Chat-V1-5#
Introduction#
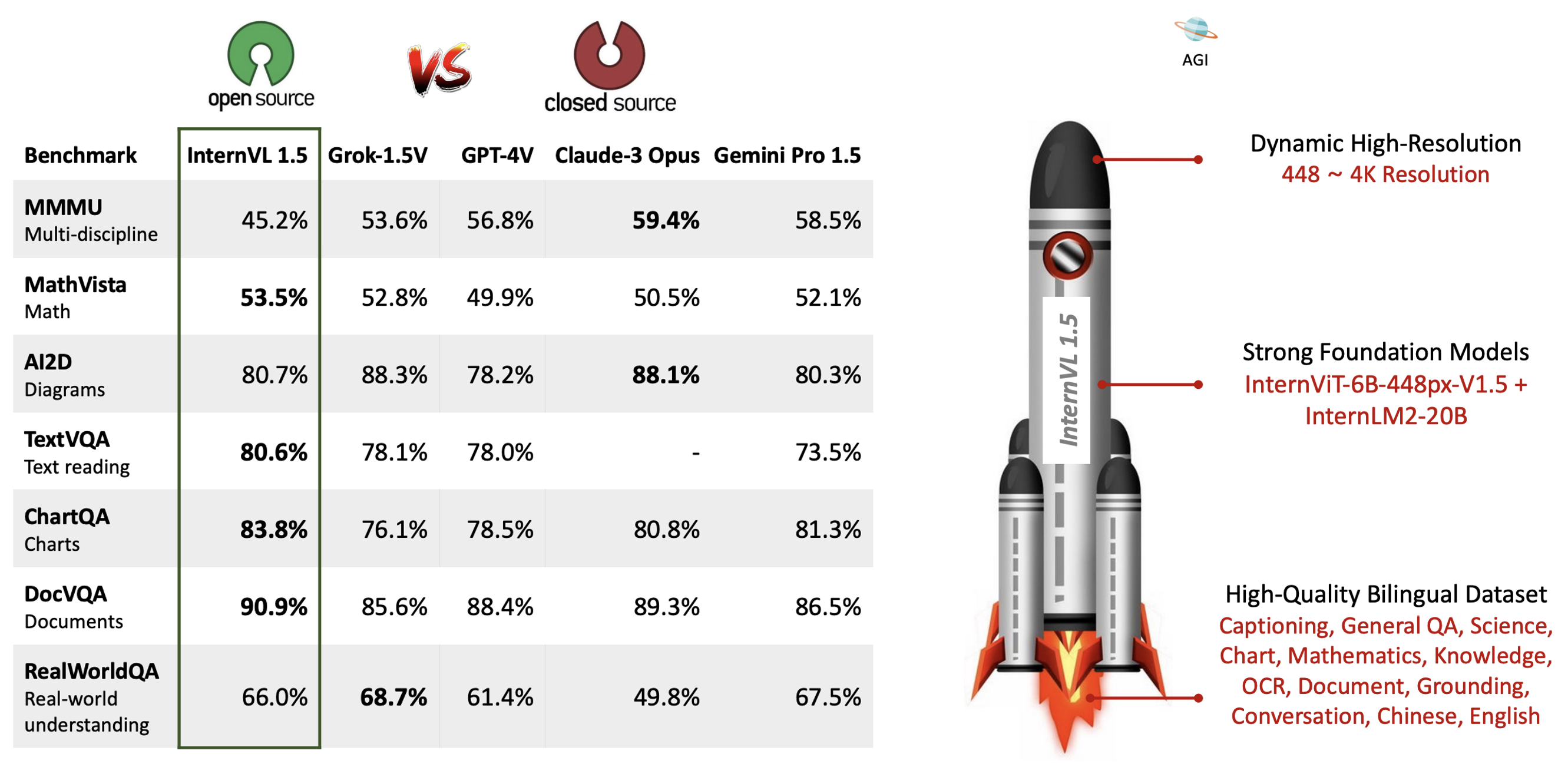
We introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple designs:
Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model——InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs.
Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448 × 448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input.
High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks.
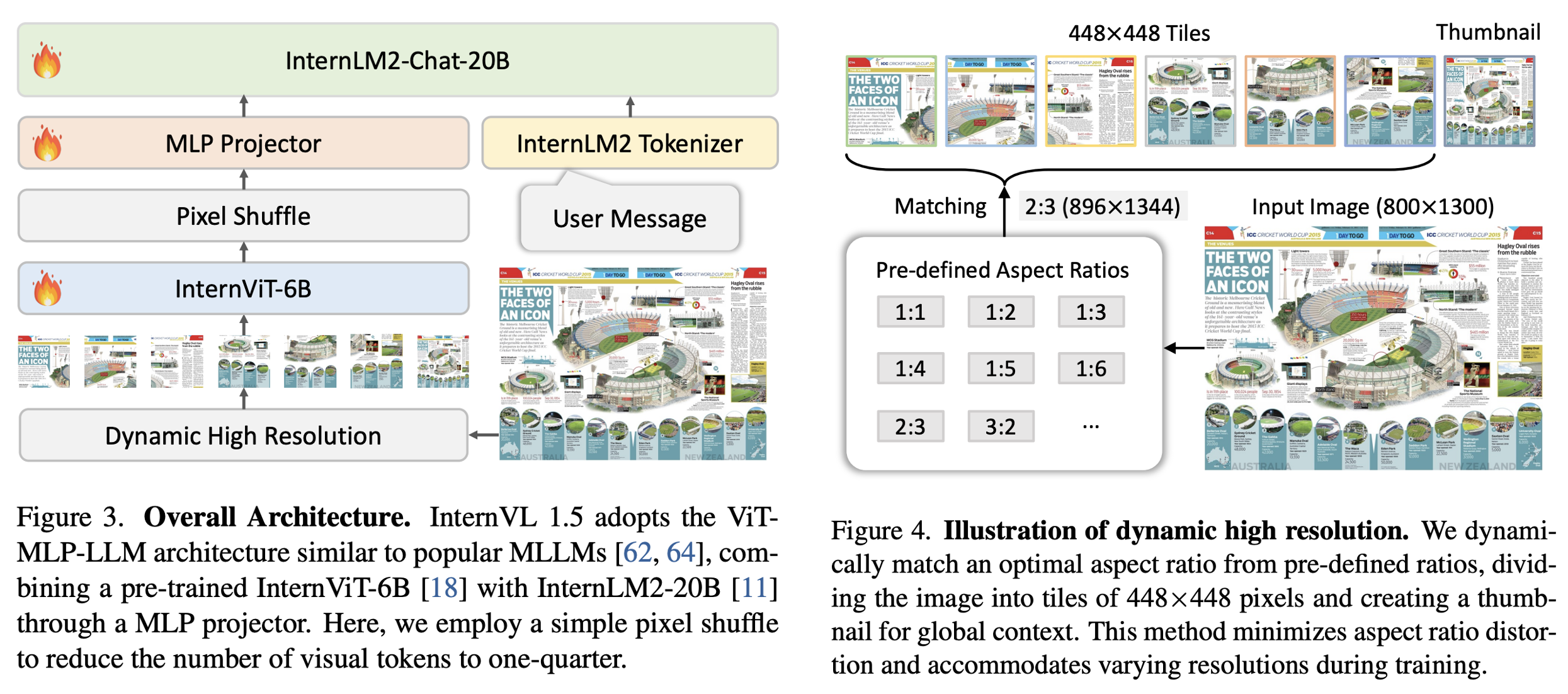
As illustrated in Figure 3, InternVL 1.5 employs an architecture akin to widely-used open-source MLLMs, specifically the “ViT-MLP-LLM” configuration referenced in various existing studies. Our implementation of this architecture integrates a pre-trained InternViT-6B with a pre-trained InternLM2-20B using a randomly initialized MLP projector.
During training, we implemented a dynamic resolution strategy, dividing images into tiles of 448 × 448 pixels in sizes ranging from 1 to 12, based on the aspect ratio and resolution of the input images. During testing, this can be zero-shot scaled up to 40 tiles (i.e., 4K resolution). To enhance scalability for high resolution, we simply employed a pixel shuffle (unshuffle) operation to reduce the number of visual tokens to one-quarter of the original. Therefore, in our model, a 448 × 448 image is represented by 256 visual tokens.
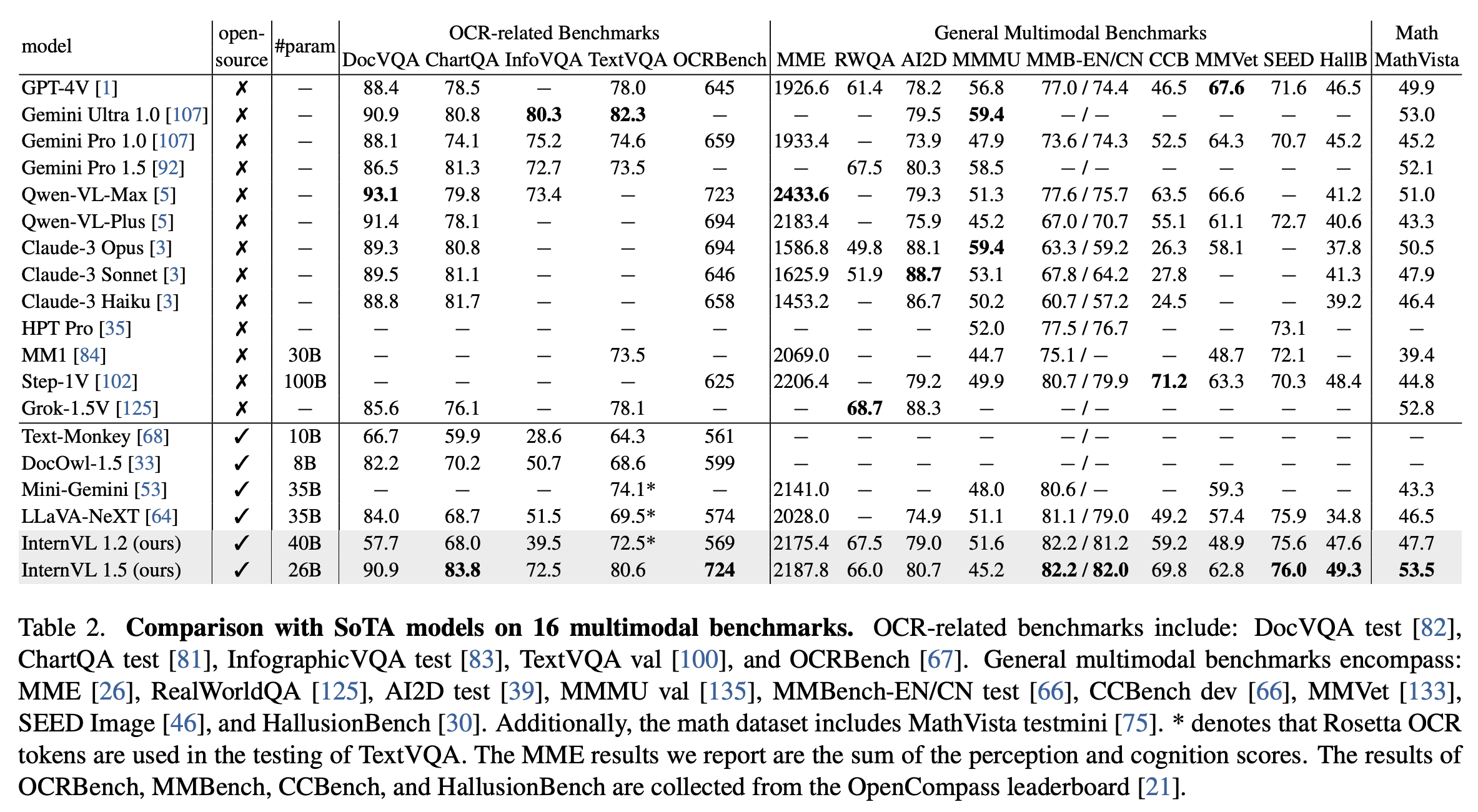
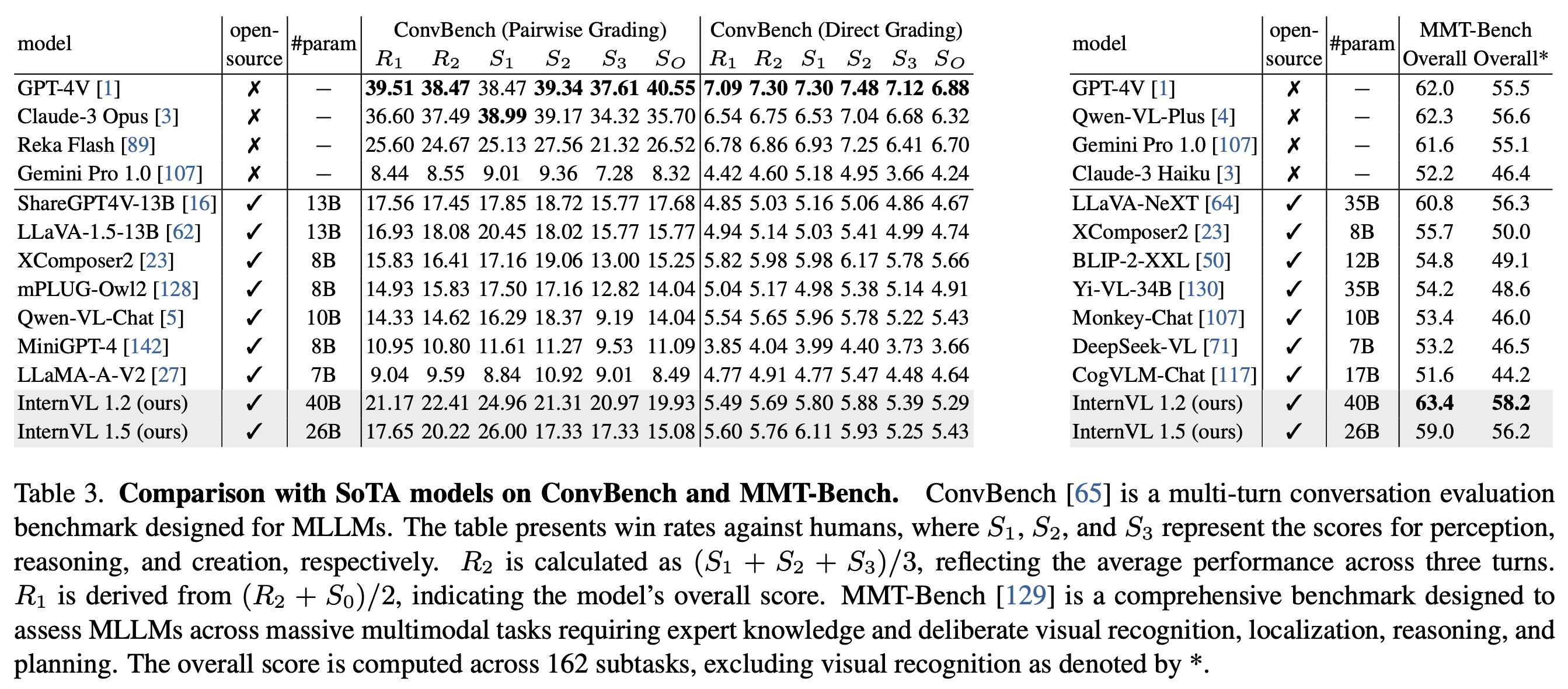
Performance#
Mini-InternVL-Chat-2B/4B-V1-5#
Introduction#
You can run multimodal large models using a 1080Ti now.
We are delighted to introduce Mini-InternVL-Chat series. In the era of large language models, many researchers have started to focus on smaller language models, such as Gemma-2B, Qwen-1.8B, and InternLM2-1.8B. Inspired by their efforts, we have distilled our vision foundation model InternViT-6B-448px-V1-5 down to 300M and used InternLM2-Chat-1.8B or Phi-3-mini-128k-instruct as our language model. This resulted in a small multimodal model with excellent performance.
As shown in the figure below, we adopted the same model architecture as InternVL 1.5. We simply replaced the original InternViT-6B with InternViT-300M and InternLM2-Chat-20B with InternLM2-Chat-1.8B or Phi-3-mini-128k-instruct. For training, we used the same data as InternVL 1.5 to train this smaller model. Additionally, due to the lower training costs of smaller models, we used a context length of 8K during training.
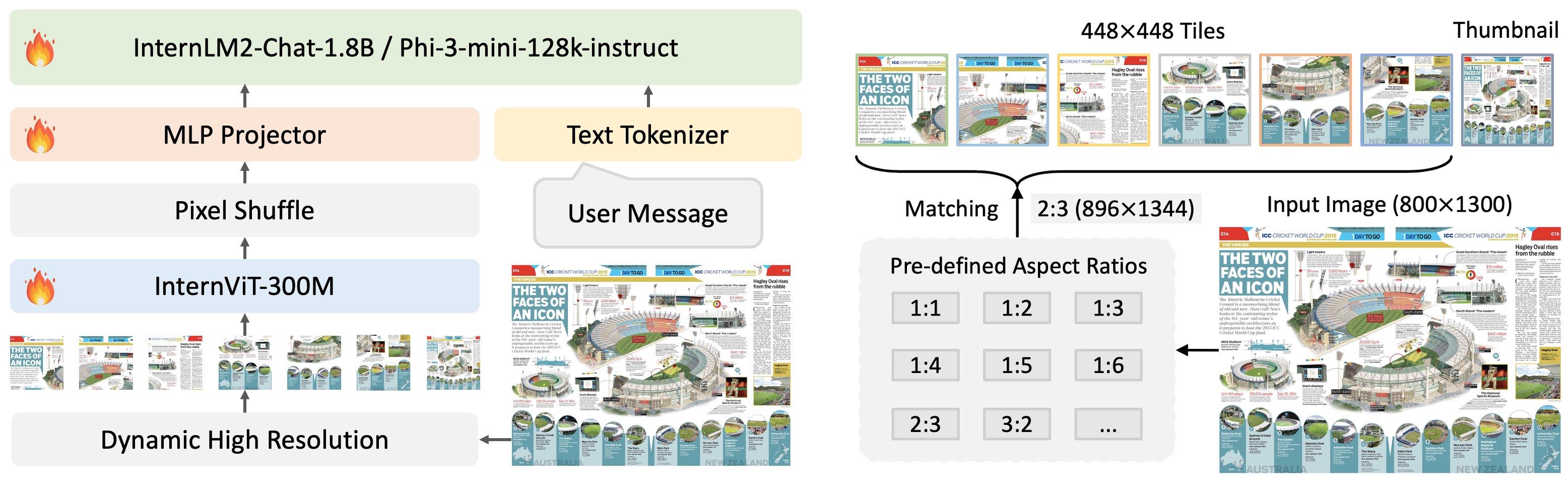
From the experimental results, we’ve observed that our distilled small vision model (InternViT-300M) is well-suited for a smaller language model (1.8B or 3.8B). This combination maximizes efficiency while maintaining impressive performance across various benchmarks, demonstrating the effectiveness of small models in handling complex tasks. Additionally, our small model significantly reduces memory requirements, making it more accessible and efficient for practical use.
Performance#
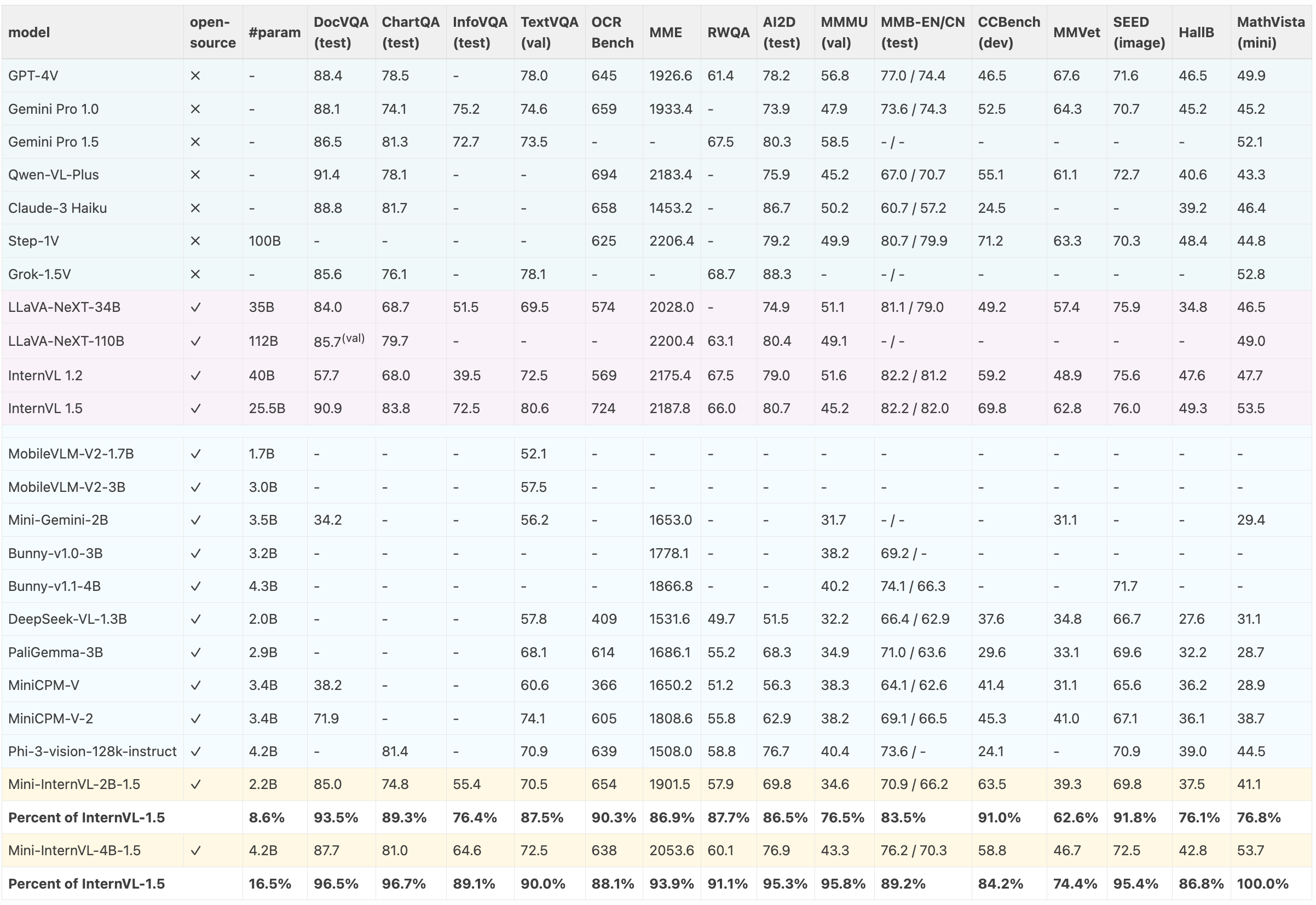
Comparison with SoTA models on 16 multimodal benchmarks. OCR-related benchmarks include: DocVQA test, ChartQA average test, InfographicVQA test, TextVQA val, and OCRBench. General multimodal benchmarks encompass: MME, RealWorldQA, AI2D test, MMMU val, MMBench-EN/CN test, CCBench dev, MMVet, SEED Image, and HallusionBench. Additionally, the math dataset includes MathVista testmini. The MME results we report are the sum of the perception and cognition scores. The results of OCRBench, MMBench, CCBench, and HallusionBench are collected from the OpenCompass leaderboard.
Citation#
If you find this project useful in your research, please consider citing:
@article{chen2024far,
title={How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={Science China Information Sciences},
volume={67},
number={12},
pages={220101},
year={2024},
publisher={Springer}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}