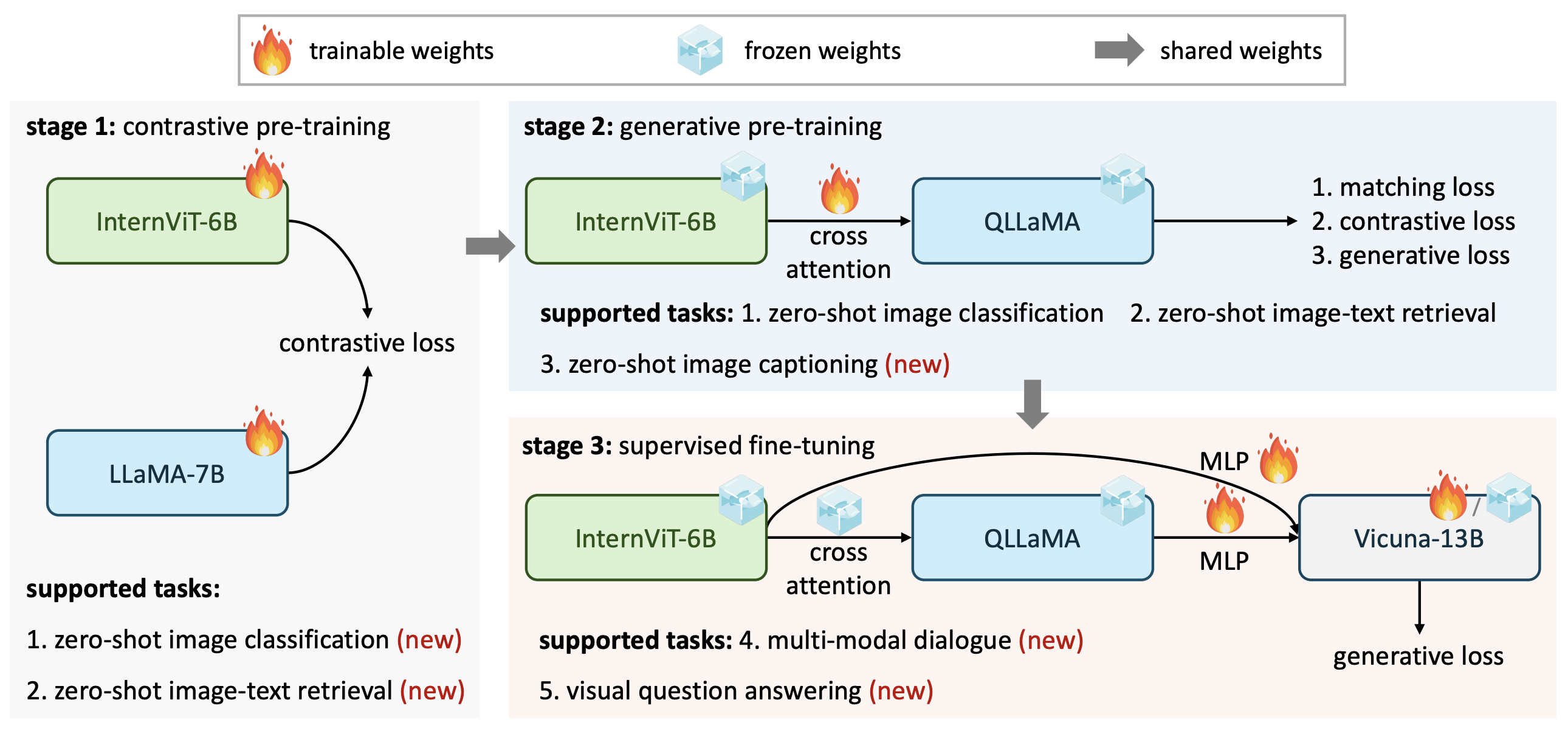
InternVL Stage-2 Pre-training & Retrieval Fine-tuning#
This folder contains the implementation of the InternVL 1.0 for stage2 pre-training and retrieval fine-tuning, which corresponds to Section 4.3 of our InternVL 1.0 paper.
Data Preparation#
Three datasets need to be prepared: COCO Caption, Flickr30K, and NoCaps.
COCO Caption
mkdir -p data/coco && cd data/coco
# download coco images
wget http://images.cocodataset.org/zips/train2014.zip && unzip train2014.zip
wget http://images.cocodataset.org/zips/val2014.zip && unzip val2014.zip
wget http://images.cocodataset.org/zips/test2015.zip && unzip test2015.zip
mkdir -p annotations && cd annotations/
# download converted annotation files
wget https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json
wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test.json
wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test_gt.json
cd ../../../
Flickr30K
mkdir -p data/flickr30k && cd data/flickr30k
# download images from https://bryanplummer.com/Flickr30kEntities/
# karpathy split annotations can be downloaded from the following link:
# https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_test_karpathy.txt
# this file is provided by the clip-benchmark repository.
# We convert this txt file to json format, download the converted file:
wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_cn_test.txt
wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_cn_train.txt
wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_test_karpathy.json
wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_test_karpathy.txt
wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_train_karpathy.txt
wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_val_karpathy.txt
cd ../..
NoCaps
mkdir -p data/nocaps && cd data/nocaps
# download images from https://nocaps.org/download
# original annotations can be downloaded from https://nocaps.s3.amazonaws.com/nocaps_val_4500_captions.json
wget https://nocaps.s3.amazonaws.com/nocaps_val_4500_captions.json
cd ../..
After the download is complete, the directory structure is:
data
├── coco
│ ├── annotations
│ │ ├── coco_karpathy_train.json
│ ├── test2017
│ ├── train2014
│ ├── train2017
│ ├── val2014
│ └── val2017
├── flickr30k
│ ├── flickr30k_cn_test.txt
│ ├── flickr30k_cn_train.txt
│ ├── flickr30k_test_karpathy.json
│ ├── flickr30k_test_karpathy.txt
│ ├── flickr30k_train_karpathy.txt
│ ├── flickr30k_val_karpathy.txt
│ └── Images
└── nocaps
├── images
└── nocaps_val_4500_captions.json
Model Preparation#
model name |
type |
param |
download |
size |
|---|---|---|---|---|
InternVL-14B-224px |
huggingface |
13.8B |
🤗 HF link |
27.7 GB |
Download the above model weights and place them in the pretrained/ folder.
cd pretrained/
# pip install -U huggingface_hub
huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-14B-224px --local-dir InternVL-14B-224px
The directory structure is:
pretrained
└── InternVL-14B-224px/
Generative Pre-training#
There are currently no plans to release this part of the code.
Evaluation#
Zero-Shot Image Captioning#
model |
dataset |
BLEU4 |
METEOR |
CIDEr |
|---|---|---|---|---|
InternVL-G |
COCO Karpathy test |
37.1 |
30.1 |
128.2 |
InternVL-G |
Flickr30K Karpathy test |
27.0 |
25.3 |
79.2 |
InternVL-G |
NoCaps val |
44.3 |
30.1 |
113.7 |
[InternVL-G] COCO Karpathy test
sh evaluate.sh pretrained/InternVL-14B-224px caption-coco
Expected results:
['coco', 'English caption:', 10.5974, dict_items([('Bleu_1', 0.7876323287981284), ('Bleu_2', 0.6353512494727918), ('Bleu_3', 0.49108984183589743), ('Bleu_4', 0.37062736733849205), ('METEOR', 0.30106315496945923), ('ROUGE_L', 0.5898249189475652), ('CIDEr', 1.281844384075423)])]
[InternVL-G] Flickr30K Karpathy test
sh evaluate.sh pretrained/InternVL-14B-224px caption-flickr30k
Expected results:
['flickr30k', 'English caption:', 10.666, dict_items([('Bleu_1', 0.7182900534357628), ('Bleu_2', 0.5353390037921949), ('Bleu_3', 0.3834462132295285), ('Bleu_4', 0.2702131471765472), ('METEOR', 0.25263515267930103), ('ROUGE_L', 0.5305876871149064), ('CIDEr', 0.7919734768328237)])]
[InternVL-G] NoCaps val
sh evaluate.sh pretrained/InternVL-14B-224px caption-nocaps
Expected results:
['nocaps', 'English caption:', 10.463111111111111, dict_items([('Bleu_1', 0.8518290482155187), ('Bleu_2', 0.7165227921485106), ('Bleu_3', 0.5733723839888316), ('Bleu_4', 0.44268902150723105), ('METEOR', 0.30078174807736896), ('ROUGE_L', 0.6070208063052156), ('CIDEr', 1.1371742045267772)])]
Fine-tuned Image-Text Retrieval#
Flickr30K fine-tuned model: InternVL-14B-Flickr30K-FT-364px#
| model | Flickr30K | avg | |||||
| image-to-text | text-to-image | ||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVL-C-FT | 97.2 | 100.0 | 100.0 | 88.5 | 98.4 | 99.2 | 97.2 |
| InternVL-G-FT | 97.9 | 100.0 | 100.0 | 89.6 | 98.6 | 99.2 | 97.6 |
[InternVL-C-FT] Flickr30K
cd ../clip_benchmark/
CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "en" --task "zeroshot_retrieval" \
--dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_c_retrieval_hf \
--pretrained ./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10/ --output result_ft.json
Expected results:
{"dataset": "flickr30k", "model": "internvl_c_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10", "task": "zeroshot_retrieval",
"metrics": {"image_retrieval_recall@1": 0.8853999972343445, "text_retrieval_recall@1": 0.972000002861023,
"image_retrieval_recall@5": 0.9836000204086304, "text_retrieval_recall@5": 1.0,
"image_retrieval_recall@10": 0.9923999905586243, "text_retrieval_recall@10": 1.0}, "language": "en"}
[InternVL-G-FT] Flickr30K
cd ../clip_benchmark/
CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "en" --task "zeroshot_retrieval" \
--dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_g_retrieval_hf \
--pretrained ./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10/ --output result_ft.json
Expected results:
{"dataset": "flickr30k", "model": "internvl_g_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10", "task": "zeroshot_retrieval",
"metrics": {"image_retrieval_recall@1": 0.895799994468689, "text_retrieval_recall@1": 0.9789999723434448,
"image_retrieval_recall@5": 0.9861999750137329, "text_retrieval_recall@5": 1.0,
"image_retrieval_recall@10": 0.9922000169754028, "text_retrieval_recall@10": 1.0}, "language": "en"}
Flickr30K-CN fine-tuned model: InternVL-14B-FlickrCN-FT-364px#
| model | Flickr30K-CN | avg | |||||
| image-to-text | text-to-image | ||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVL-C-FT | 96.5 | 99.9 | 100.0 | 85.2 | 97.0 | 98.5 | 96.2 |
| InternVL-G-FT | 96.9 | 99.9 | 100.0 | 85.9 | 97.1 | 98.7 | 96.4 |
[InternVL-C-FT] Flickr30K-CN
cd ../clip_benchmark/
CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "cn" --task "zeroshot_retrieval" \
--dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_c_retrieval_hf \
--pretrained ./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10/ --output result_ft.json
Expected results:
{"dataset": "flickr30k", "model": "internvl_c_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10", "task": "zeroshot_retrieval",
"metrics": {"image_retrieval_recall@1": 0.8521999716758728, "text_retrieval_recall@1": 0.9649999737739563,
"image_retrieval_recall@5": 0.9697999954223633, "text_retrieval_recall@5": 0.9990000128746033,
"image_retrieval_recall@10": 0.9854000210762024, "text_retrieval_recall@10": 1.0}, "language": "cn"}
[InternVL-G-FT] Flickr30K-CN
cd ../clip_benchmark/
CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "cn" --task "zeroshot_retrieval" \
--dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_g_retrieval_hf \
--pretrained ./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10/ --output result_ft.json
Expected results:
{"dataset": "flickr30k", "model": "internvl_g_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10", "task": "zeroshot_retrieval",
"metrics": {"image_retrieval_recall@1": 0.8587999939918518, "text_retrieval_recall@1": 0.968999981880188,
"image_retrieval_recall@5": 0.9714000225067139, "text_retrieval_recall@5": 0.9990000128746033,
"image_retrieval_recall@10": 0.9865999817848206, "text_retrieval_recall@10": 1.0}, "language": "cn"}
Retrieval Fine-tuning (Fully)#
Note: In our experiments, full parameter fine-tuning achieves the best results on image-text retrieval tasks in Flickr30K and COCO. By following the experimental hyperparameters in this section, you can reproduce the model performance reported in the Evaluation section.
To fine-tune InternVL on Flickr30K with 32 GPUs and slurm system, run:
PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_flickr_364_bs1024_ep10.sh
To fine-tune InternVL on Flickr30K-CN with 32 GPUs and slurm system, run:
PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_flickrcn_364_bs1024_ep10.sh
To fine-tune InternVL on COCO with 32 GPUs and slurm system, run:
PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_coco_364_bs1024_ep5.sh
The hyperparameters used here are:
config |
Flickr30K |
Flickr30K-CN |
COCO |
|---|---|---|---|
learning rate |
1e-6 |
1e-6 |
1e-6 |
layer-wise lr |
InternViT-6B (0.9), |
InternViT-6B (0.9), |
InternViT-6B (0.9), |
optimizer |
AdamW |
AdamW |
AdamW |
weight decay |
0.05 |
0.05 |
0.05 |
input resolution |
364x364 |
364x364 |
364x364 |
total batch size |
1024 |
1024 |
1024 |
warm-up iterations |
100 |
100 |
100 |
training epochs |
10 |
10 |
5 |
drop path rate |
0.3 |
0.3 |
0.3 |
numerical precision |
zero1 + bf16 |
zero1 + bf16 |
zero1 + bf16 |
trainable / total params |
14B / 14B |
14B / 14B |
14B / 14B |
GPUs for training |
32×A100 (80G) |
32×A100 (80G) |
32×A100 (80G) |
Required GPU memory |
80G |
80G |
80G |
Retrieval Fine-tuning (Head)#
Note: This section demonstrates how to perform a cost-effective fine-tuning of our model. The hyperparameters shown here are not optimized for any specific task. For practical applications, further adjustments to the hyperparameters may be necessary to achieve optimal performance.
To fine-tune the head of InternVL on Flickr30K with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 sh shell/head_finetune/internvl_stage2_finetune_flickr_224_bs1024_ep10_head_4gpu.sh
To fine-tune the head of InternVL on Flickr30K-CN with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 sh shell/head_finetune/internvl_stage2_finetune_flickrcn_224_bs1024_ep10_head_4gpu.sh
To fine-tune the head of InternVL on COCO with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 shell/head_finetune/internvl_stage2_finetune_coco_224_bs1024_ep5_head_4gpu.sh
The hyperparameters used here are:
config |
Flickr30K |
Flickr30K-CN |
COCO |
|---|---|---|---|
learning rate |
1e-6 |
1e-6 |
1e-6 |
optimizer |
AdamW |
AdamW |
AdamW |
weight decay |
0.05 |
0.05 |
0.05 |
input resolution |
224x224 |
224x224 |
224x224 |
total batch size |
4x32 |
4x32 |
4x32 |
warm-up iterations |
100 |
100 |
100 |
training epochs |
10 |
10 |
5 |
drop path rate |
0.0 |
0.0 |
0.3 |
numerical precision |
zero3 + bf16 |
zero3 + bf16 |
zero1 + bf16 |
trainable / total params |
0.2B / 14B |
0.2B / 14B |
0.2B / 14B |
GPUs for training |
4×GPU (>=32G) |
4×GPU (>=32G) |
4×GPU (>=32G) |
Required GPU memory |
24G |
24G |
24G |
Retrieval Fine-tuning (LoRA)#
Note: This section demonstrates how to perform a cost-effective fine-tuning of our model. The hyperparameters shown here are not optimized for any specific task. For practical applications, further adjustments to the hyperparameters may be necessary to achieve optimal performance.
To fine-tune InternVL using LoRA on Flickr30K with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 sh shell/lora_finetune/internvl_stage2_finetune_flickr_224_bs1024_ep10_lora16_4gpu.sh
To fine-tune InternVL using LoRA on Flickr30K-CN with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 sh shell/lora_finetune/internvl_stage2_finetune_flickrcn_224_bs1024_ep10_lora16_4gpu.sh
To fine-tune InternVL using LoRA on COCO with 4 GPUs, run:
GPUS=4 BATCH_SIZE=32 shell/lora_finetune/internvl_stage2_finetune_coco_224_bs1024_ep5_lora16_4gpu.sh
The hyperparameters used here are:
config |
Flickr30K |
Flickr30K-CN |
COCO |
|---|---|---|---|
learning rate |
1e-6 |
1e-6 |
1e-6 |
optimizer |
AdamW |
AdamW |
AdamW |
lora rank |
16 |
16 |
16 |
weight decay |
0.05 |
0.05 |
0.05 |
input resolution |
224x224 |
224x224 |
224x224 |
total batch size |
4x32 |
4x32 |
4x32 |
warm-up iterations |
100 |
100 |
100 |
training epochs |
10 |
10 |
5 |
drop path rate |
0.0 |
0.0 |
0.3 |
numerical precision |
zero3 + bf16 |
zero3 + bf16 |
zero1 + bf16 |
trainable / total params |
0.3B / 14B |
0.3B / 14B |
0.3B / 14B |
GPUs for training |
4×GPU (>=40G) |
4×GPU (>=40G) |
4×GPU (>=40G) |
Required GPU memory |
37G |
37G |
37G |
Fine-Tuning a Custom Dataset#
Organize Your Data: Format your dataset similar to COCO or Flickr30K.
Update Meta Information: Add your dataset’s meta information to the
ds_collectionsdictionary ininternvl_g/internvl/train/internvl_stage2_finetune.py. For example:ds_collections = { 'my_dataset_flickr_format': { 'root': './data/my_dataset/images/', 'annotation': './data/my_dataset/annotations.txt', }, 'my_dataset_coco_format': { 'root': './data/my_dataset/', 'annotation': './data/my_dataset/annotations.json', }, }
Name Your Dataset:
Include
flickr_formatorcoco_formatin your dataset’sdataset_name. This will allow the script to reuse the Flickr30K or COCO dataloader accordingly.
By following these steps, you can easily fine-tune the InternVL model on your custom dataset using the existing COCO or Flickr30K data loading mechanisms.
Citation#
If you find this project useful in your research, please consider citing:
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}